Opensource 开源项目与数据
Toolkits
 ReChorusTop-K Recommendation with Implicit Feedback
ReChorusTop-K Recommendation with Implicit FeedbackReChorus is a general PyTorch framework for Top-K recommendation with implicit feedback, especially for research purpose. It aims to provide a fair benchmark to compare different state-of-the-art algorithms. We hope this can partially alleviate the problem that different papers adopt non-comparable experimental settings, so as to form a “Chorus” of recommendation algorithms.
 ULTRAUnbiased Learning to Rank Algorithm
ULTRAUnbiased Learning to Rank AlgorithmULTRA is an Unbiased Learning To Rank Algorithms toolbox that provides a codebase for experiments and research on learning to rank with human annotated or noisy labels. With the unified data processing pipeline, ULTRA supports multiple unbiased learning-to-rank algorithms, online learning-to-rank algorithms, neural learning-to-rank models, as well as different methods to use and simulate noisy labels (e.g., clicks) to train and test different algorithms/ranking models
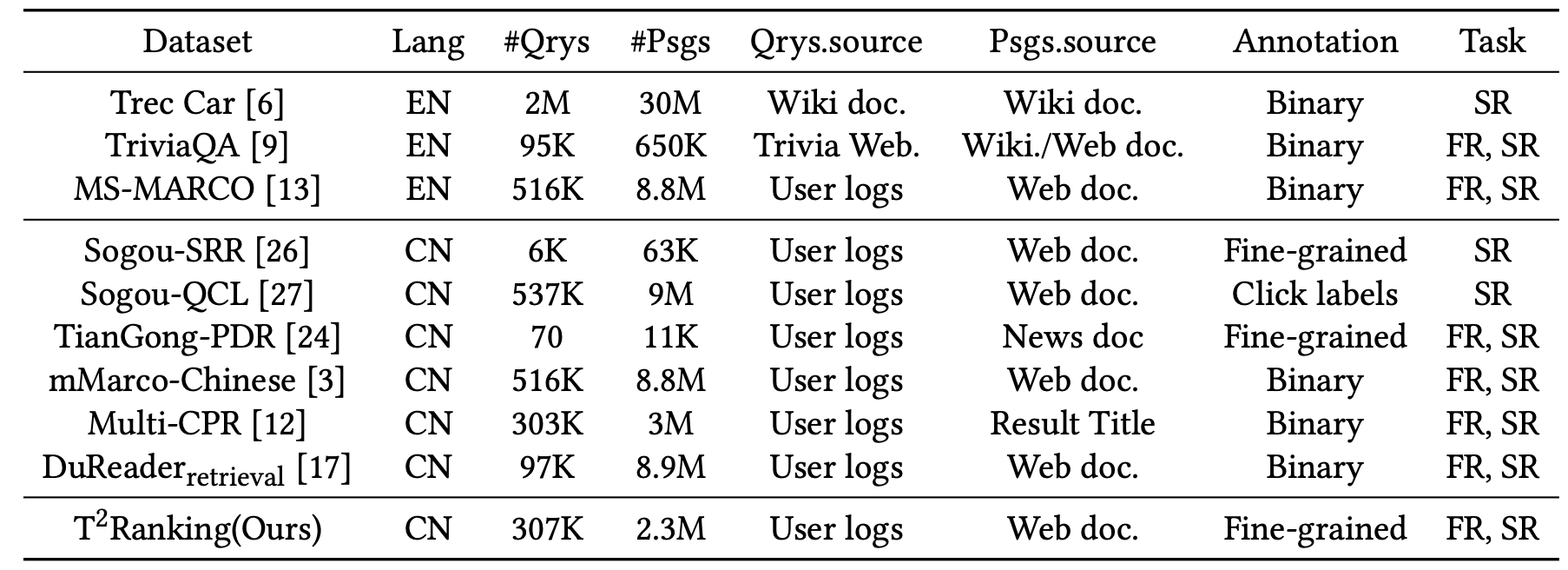
Datasets
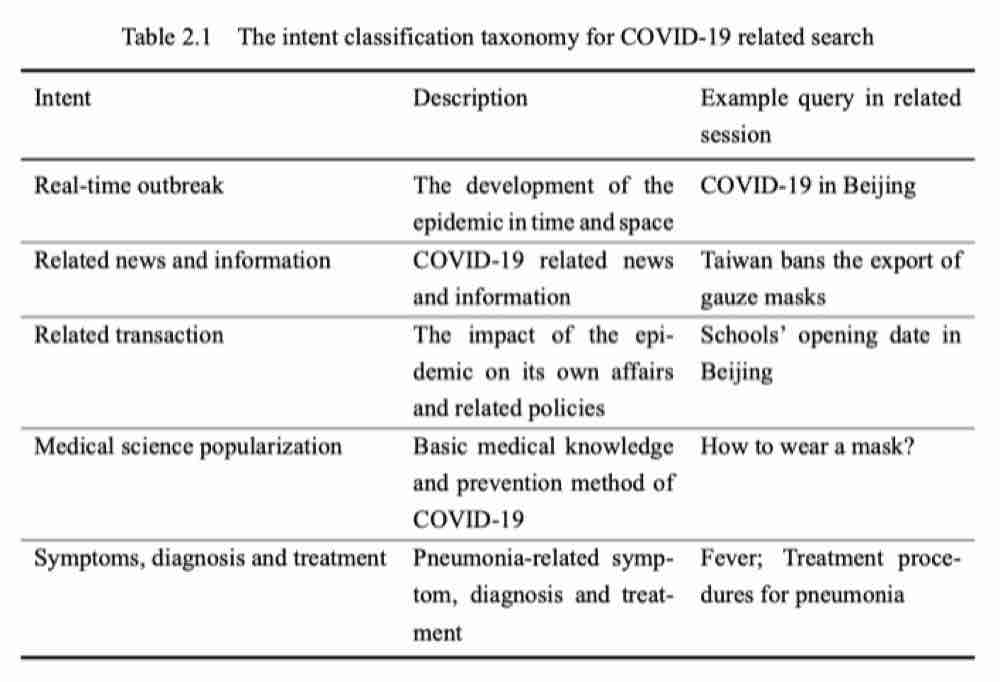
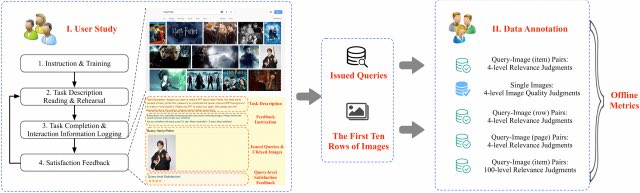
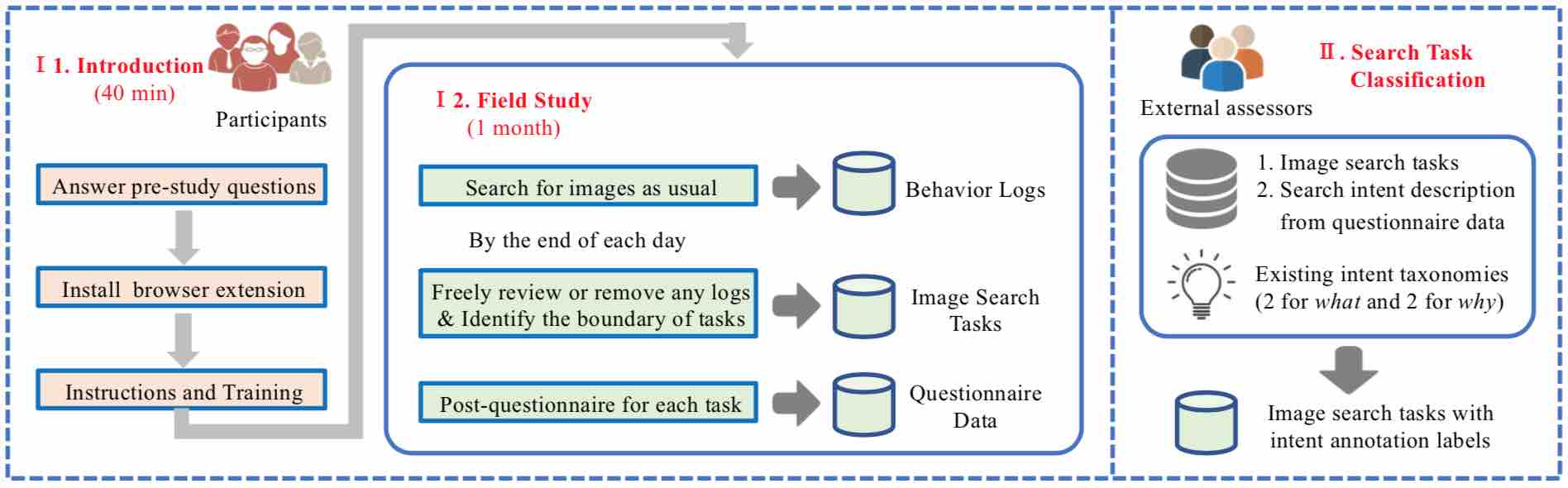
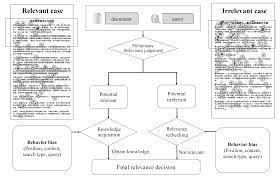

Special thanks to Shuqi Zhu for the initial construction of this page.